No Results Found
2025/5/24
506 字
Dirac/Schrodinger轨道可视化
2024/12/29
107 字
已迁移到Astro
2024/12/16
463 字
413468张图片(2007-2024)统计结果
2024/11/25
2135 字
基于 DeepDanbooru CLIP PaddleOCR
2024/11/24
460 字
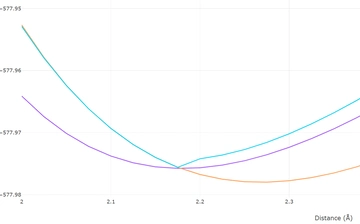
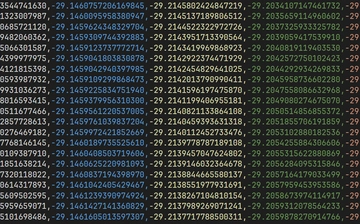
Si2 扫描 2.00~2.70(步长0.0025)
122 字
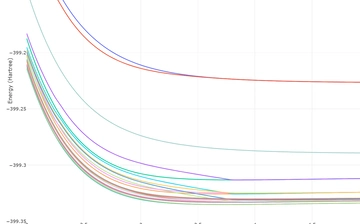
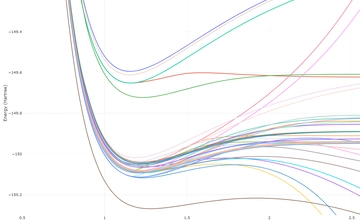
Mg2 扫描 2.00~10.0(步长0.05)
242 字
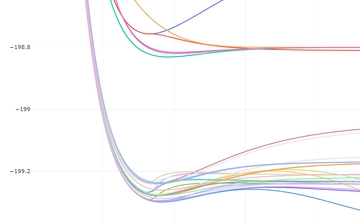
Be2 扫描 0.40~8.0(步长0.05)
2024/10/22
435 字
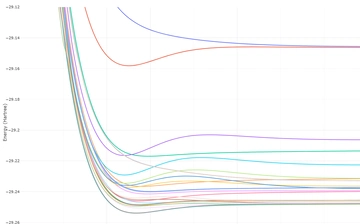
O2(单重态) 扫描 0.05~2.55(步长0.05)
2024/9/24
116 字
Scan脚本
2024/9/10
900 字
F2 扫描 0.05~19.95(步长0.05)