
PxIMSE
基于DeepDanbooru, CLIP 和 PaddleOCR的本地图像搜索
GitHub: PxIMSE
MongoDB 存储图片信息、DeepDanbooru 和 OCR 结果,CLIP 结果存储在向量数据库 Milvus
支持的文件名格式
图片来自 Pixiv, PixivBatchDownloader, PixEZ … , Twitter Media Downloader, yande.re 或者其他来源,但是DB中不会记录id信息:
- pixiv: {user_id}_{id}_p{index} (建议)
- pixiv: {id}_p{index}
- twitter: twitter_{user_name}(@{user_id})_{date}_{id}_photo
- yande.re: yande.re {id} {tags}
Pre-requisites
DB配置参考docker-compose.yml
安装依赖
pip3 install -r requirements.txttorch、tensorflow、paddlepaddle所需CUDA环境可能冲突,需要手动配置
pnpm install配置
python/config.yml配置图片文件夹和DB设置
需要其他CLIP模型请更改clip1.py和milvus.py,默认使用最便宜的OpenAI ViT-B/32(输出512维向量,其他模型可能是768维)
config.mjs配置Nginx和API地址
使用方法
导入图片
- 导入MongoDB
python import_images.py mongo- 导入CLIP结果到Milvus
python import_images.py milvus- 从Pixiv获取图片信息 (可选)
python import_images.py pixiv- 尝试将数据库中文档的
username分配给相同userid但没有username的文档 (必须给userid和username建立索引,否则非常耗时) (可选)
python import_images.py update- 导入OCR结果到meilisearch (可选)
python import_images.py meili2. 启动服务
cd python
uvicorn api:app --host 0.0.0.0 --port 8000pnpm dev说明
MongoDB文档结构:
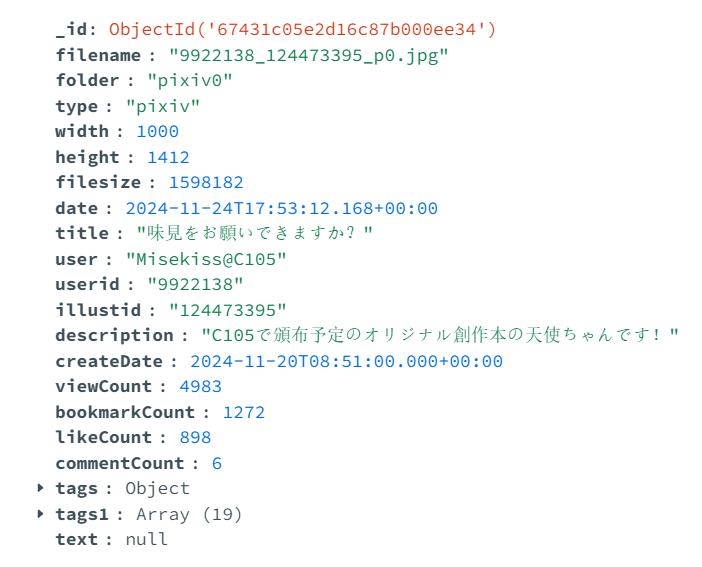
tags为DeepDanbooru识别结果
tags1是从Pixiv获取到的结果,对于yandere图片为文件名内包含的标签
Query 部分格式:
存在:
tags.xxx
tags1:xxx (AND)
|tags1:xxx (OR)
不存在:
!tags.xxx
!tags1:xxx
大于、小于、等于、不等于
filesize;>1000000
tags.xxx;<=0.9
likeCount;=100
viewCount;!=200
多个条件:
date;>2000-01-01&<2010-01-01
字符串:
userid;=“12345”
OCR文本内容(meilisearch):
m;xxx
OCR文本长度:
textlen;>xx
textlen;<=xx
Sort 部分格式:
升序: filesize;1
降序: filesize 或 filesize;-1
Milvus
Milvus 部分默认使用基于图的 HNSW 索引,M值取32,efConstruction为64(未经充分测试)
该索引比 FLAT(对于每个查询都计算数据库中所有向量)快至少3倍(未经充分测试)
取值过高建立索引的速度可能十分缓慢
向量归一化后再存入 Milvus ,以内积衡量向量距离
Milvus 的GPU版本还支持GPU索引,但是目前只支持 FP32
Milvus 向量查询结果最多只能返回 16,384 条记录
消失的Pixiv图片
2019-2024保存的44万图片在第3步导入完成后大约有 1/13 记录到 errors(p站上找不到该图片)
对于作者图片没有删除完全的情况,第4步可以尝试将数据库中文档的username分配给相同userid但没有username的文档(只对记录了userid的第一种文件名有效)
Inspired by: clip-image-search