
计算xyz动画每一帧的molden
xyz动画由opt,IRC,scan,MD等任务生成,计算每一帧的单点可以研究(反应)过程中电子结构的变化
参考通过键级曲线和ELF/LOL/RDG等值面动画研究化学反应过程
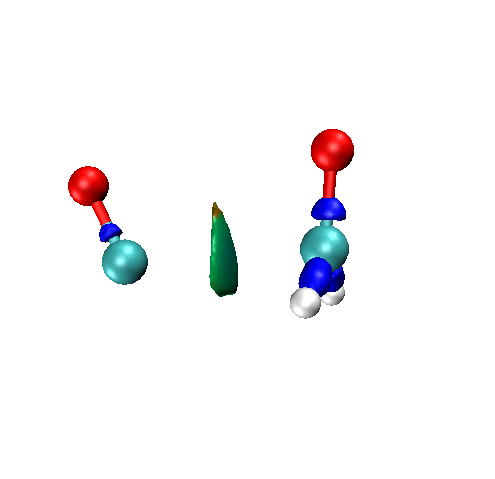
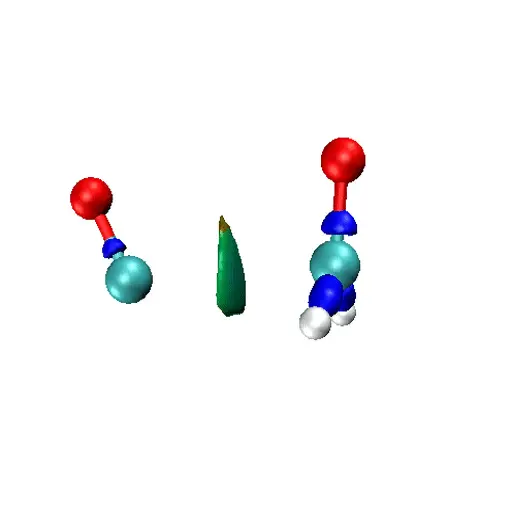 图为CO+H2CO反应IRC的IRI动画,使用ffmpeg将VMD输出的.bmp转为mp4/gif
图为CO+H2CO反应IRC的IRI动画,使用ffmpeg将VMD输出的.bmp转为mp4/gif
其实已经有人写过类似的程序了(
- 将多帧xyz文件转化成量子化学输入文件的工具:xyz2QC - 量子化学 (Quantum Chemistry) - 计算化学公社
- 将多帧xyz文件生成Gaussian输入文件的批处理脚本。 - 资源分享 - 计算化学公社
- 将Gaussian的IRC任务输出转换为.xyz轨迹文件的工具:GauIRC2xyz - 思想家公社的门口:量子化学·分子模拟·二次元
- 谈谈记录化学体系结构的xyz文件 - 思想家公社的门口:量子化学·分子模拟·二次元
对于IRC,可以将Gaussian与ORCA联用输出每一步的gbw
trj2inp: 生成xyz动画每一帧的ORCA输入文件
也可以生成其他软件的输入文件,但是如果要运行的话需要自己写对应的runall.sh
使用方法: ./trj2inp.sh trj.xyz template.inp
注意输入的xyz和inp文件名不能为数字,否则可能会被覆盖,导致错误
需要一个ORCA输入文件模板:
将输入文件中的xyz部分用[geometry]替代,例如:
! B3LYP D3 def2-TZVP def2/J RIJCOSX noautostart miniprint nopop
%maxcore 1000
%pal nprocs 8 end
* xyz 0 1
[geometry]
*#!/bin/bash
xyzfilename=$1
inp=$2
number=$(awk '{print $1}' $xyzfilename | head -1)
rownumber=$(awk '{print NR}' $xyzfilename|tail -1)
xyznumber=$((rownumber / (number + 2)))
for ((i=1; i<=$xyznumber; i=i+1))
do
startline=$(((i - 1)*(number + 2)+3))
endline=$((startline + number - 1))
sed -n "${startline},${endline-1}p" $xyzfilename > temp.txt
new_startline=$(grep -n -i '\[geometry\]' $inp | awk -F : '{print $1}')
sed "${new_startline}r temp.txt" $inp > $i.inp
sed -i "/\[geometry\]/I d" $i.inp
done
rm temp.txt
orcarunall: 运行所有ORCA输入文件
请提前移除/重命名模板输入文件
#!/bin/bash
# 修改自http://sobereva.com/258
# orca路径
orca_path=/home/usu171/downloads/orca_5_0_4
icc=0
nfile=`ls ./*.inp|wc -l`
for inf in *.inp
do
((icc++))
echo Running ${inf} ... \($icc of $nfile\)
time $orca_path/orca ${inf} > ${inf/inp/out}
$orca_path/orca_2mkl ${inf/.inp} -molden
echo ${inf} has finished
echo
donetrj2xyz: 将xyz动画拆分为单独的.xyz文件
也可以用split拆分文件
使用方法: ./trj2xyz.sh trj.xyz
注意输入的xyz文件名不能为数字,否则可能会被覆盖,导致错误
#!/bin/bash
xyzfilename=$1
number=$(awk '{print $1}' $xyzfilename | head -1)
rownumber=$(awk '{print NR}' $xyzfilename|tail -1)
xyznumber=$((rownumber / (number + 2)))
for ((i=1; i<=$xyznumber; i=i+1))
do
startline=$(((i - 1)*(number + 2)+1))
endline=$((startline + number + 1))
sed -n "${startline},${endline-1}p" $xyzfilename > $i.xyz
donextbrunall: 用xtb计算所有.xyz文件
请提前移除/重命名xyz动画文件
#!/bin/bash
# 修改自http://sobereva.com/258
xtb_args="--gfn 2 --chrg 0 --uhf 0 --molden"
icc=0
nfile=`ls ./*.xyz|wc -l`
for inf in *.xyz
do
((icc++))
echo Running ${inf} ... \($icc of $nfile\)
time xtb ${inf} ${xtb_args} > ${inf/xyz/out}
mv molden.input ${inf/xyz}molden.input
echo ${inf} has finished
echo
done
rm charges wbo xtbrestart xtbtopo.molbatch.sh: 调用Multiwfn生成用于IRI的cub文件
batch.sh:
for inf in *.molden.input
do
Multiwfn ${inf} < batch.txt
mv func1.cub f1_${inf/.molden.input}.cub
mv func2.cub f2_${inf/.molden.input}.cub
done根据实际情况修改
batch.txt:
20
4
4
0.1
3VMD渲染IRI动画
使用方法: 打开VMD,输入source isoall.tcl
将此文件保存到VMD安装目录
isoall.tcl
color Display Background white
color scale method BGR
color scale midpoint 0.666
display depthcue off
set isoval 1
axes location Off
display distance -8.0
light 3 on
#根据实际情况进行修改
for {set i 1} {$i<=51} {incr i} {
set name $i
puts "Processing f1_$name.cub and f2_$name.cub..."
mol default style CPK
mol new f1_$name.cub
mol addfile f2_$name.cub
# 根据实际情况进行修改
scale to 0.4
rotate y by -15
translate by 0.000000 0.00000 -2.000000
mol modstyle 0 top CPK 0.700000 0.300000 18.000000 16.000000
mol addrep top
mol modstyle 1 top Isosurface $isoval 1 0 0 1 1
mol modcolor 1 top Volume 0
mol scaleminmax top 1 -0.04 0.02
render snapshot $name.bmp
mol delete top
}reverse
如果xyz动画反了,可以翻转它
#!/bin/bash
xyzfilename=$1
number=$(awk '{print $1}' $xyzfilename | head -1)
rownumber=$(awk '{print NR}' $xyzfilename|tail -1)
xyznumber=$((rownumber / (number + 2)))
truncate -s 0 ${xyzfilename%.*}_reverse.${xyzfilename##*.}
for ((i=$xyznumber; i >= 1; i=i-1))
do
startline=$(((i - 1)*(number + 2)+1))
endline=$((startline + number + 1))
sed -n "${startline},${endline-1}p" $xyzfilename >> ${xyzfilename%.*}_reverse.${xyzfilename##*.}
done